This was originally published on the Unlocking Research blog on 5th May 2017 under a CC-BY licence.
This blog post gathers key reflections and take-home messages from a Birds of a Feather discussion on the topic of senior management engagement with RDM, and while written by a small number of attendees, the content reflects the wider discussion in the room on the day. [Authors: Silke Bellanger, Rosie Higman, Heidi Imker, Bev Jones, Liz Lyon, Paul Stokes, Marta Teperek*, Dirk Verdicchio]
On 20 February 2017, stakeholders interested in different aspects of data management and data curation met in Edinburgh to attend the 12th International Digital Curation Conference, organised by the Digital Curation Centre. Apart from discussing novel tools and services for data curation, the take-home message from many presentations was that successful development of Research Data Management (RDM) services requires the buy-in of a broad range of stakeholders, including senior institutional leadership.
Summary
The key strategies for engaging senior leadership with RDM that were discussed were:
- Refer to doomsday scenarios and risks to reputations
- Provide high profile cases of fraudulent research
- Ask senior researchers to self-reflect and ask them to imagine a situation of being asked for supporting research data for their publication
- Refer to the institutional mission statement / value statement
- Collect horror stories of poor data management practice from your research community
- Know and use your networks – know who your potential allies are and how they can help you
- Work together with funders to shape new RDM policies
- Don’t be afraid to talk about the problems you are experiencing – most likely you are not alone and you can benefit from exchanging best practice with others
Why it is important to talk about engaging senior leadership in RDM?
Endorsement of RDM services by senior management is important because frequently it is a prerequisite for the initial development of any RDM support services for the research community. However, the sensitive nature of the topic (both financially and sometimes politically as well) means there are difficulties in openly discussing the issues that RDM service developers face when proposing business cases to senior leadership. This means the scale of the problem is unknown and is often limited to occasional informal discussions between people in similar roles who share the same problems.
This situation prevents those developing RDM services from exchanging best practice and addressing these problems effectively. In order to flesh out common problems faced by RDM service developers and to start identifying possible solutions, we organised an informal Birds of a Feather discussion on the topic during the 12th IDCC conference. The session was attended by approximately 40 people, including institutional RDM service providers, senior organisational leaders, researchers and publishers.
What is the problem?
We started by fleshing out the problems, which vary greatly between institutions. Many participants said that their senior management was disengaged with the RDM agenda and did not perceive good RDM as an area of importance to their institution. Others complained that they did not even have the opportunity to discuss the issue with their senior leadership. So the problems identified were both with the conversations themselves, as well as with accessing senior management in the first place.
We explored the type of senior leadership groups that people had problems engaging with. Several stakeholders were identified: top level institutional leadership, heads of faculties and schools, library leadership, as well as some research team leaders. The types of issues experienced when interacting with these various stakeholder groups also differed.
Common themes
Next we considered if there were any common factors shared between these different stakeholder groups. One of the main issues identified was that people’s personal academic/scientific experience and historic ideals of scientific practice were used as a background for decision making.
Senior leaders, like many other people, tend to look at problems with their own perspective and experience in mind. In particular, within the rapidly evolving scholarly communication environment what they perceive as community norms (or in fact community problems) might be changing and may now be different for current researchers.
The other common issue was the lack of tangible metrics to measure and assess the importance of RDM which could be used to persuade senior management of RDM’s usefulness. The difficulties in applying objective measures to RDM activities are mostly due to the fact that every researcher is undertaking an amount of RDM by default so it is challenging to find an example of a situation without any RDM activities that could be used as a baseline for an evidenced-based cost benefit analysis of RDM. The work conducted by Jisc in this area might be able to provide some solutions for this. Current results from this work can be found on the Research Data Network website.
What works?
The core of our discussion was focused on exchanging effective methods of convincing managers and how to start gathering evidence to support the case for an RDM service within an institution.
Doomsday scenarios
We all agreed that one strategy that works for almost all possible audience types are doomsday scenarios – disasters that can happen when researchers do not adhere to good RDM practice. This could be as simple as asking individual senior researchers what they would do if someone accused them of falsifying research data five years after they have published their corresponding research paper. Would they have enough evidence to reject such accusations? The possibility of being confronted with their own potential undoing helped convince many senior managers of the importance of RDM.
Other doomsday scenarios which seem to convince senior leaders were related to broader institutional crises, such as risk of fire. Useful examples are the fire which destroyed the newly built Chemistry building at the University of Nottingham, the fire which destroyed valuable equipment and research at the University of Southampton (£120 million pounds’ worth of equipment and facilities), the recent fire at the Cancer Research UK Manchester Institute and a similar disaster at the University of Santa Cruz.
Research integrity and research misconduct
Discussion of doomsday scenarios led us to talk about research integrity issues. Reference to documented cases of fraudulent research helped some institutions convince their senior leadership of the importance of good RDM. These cases included the fraudulent research by Diederik Stapel from Tilburg University or by Erin Potts-Kant from Duke University, where $200 million in grants was awarded based on fake data. This led to a longer discussion about research reproducibility and who owns the problem of irreproducible research – individual researchers, funders, institutions or perhaps publishers. We concluded that responsibility is shared, and that perhaps the main reason for the current reproducibility crisis lies in the flawed reward system for researchers.
Research ethics and research integrity are directly connected to good RDM practice and are also the core ethical values of academia. We therefore reflected on the importance of referring to the institutional value statement/mission statement or code of conduct when advocating/arguing for good RDM. One person admitted adding a clear reference to the institutional mission statement whenever asking senior leadership for endorsement for RDM service improvements. The UK Concordat on Open Research Data is a highly regarded external document listing core expectations on good research data management and sharing, which might be worth including as a reference. In addition, most higher education institutions will have mandates in teaching and research, which might allow good RDM practice to be endorsed through their central ethics committees.
Bottom up approaches to reach the top
The discussion about ethics and the ethos of being a researcher started a conversation about the importance of bottom up approaches in empowering the research community to drive change and bring innovation. As many researcher champions as possible should convince senior leadership about important services. Researcher voices are often louder than those of librarians, or those running central support services, so consider who will best help to champion your cause.
Collecting testimonies from researchers about the difficulties of working with research data when good data management practice was not adhered to is also a useful approach. Shared examples of these included horror stories such as data loss from stolen laptops (when data had not been backed up), newly started postdocs inheriting projects and the need to re-do all the experiments from scratch due to lack of sufficient data documentation from their predecessor, or lost patent cases. One person mentioned that what worked at their institution was an ‘honesty box’ where researchers could anonymously share their horror data management stories.
We also discussed the potential role of whistle-blowers, especially given the fact that reputational damage is extremely important for institutions. There was a suggestion that institutions should add consequences of poor data management practice to their institutional risk registers. The argument that good data management practice leads to time and efficiency savings also seems to be powerful when presented to senior leadership.
The importance of social networks
We then discussed the importance of using one’s relationships in getting senior management’s endorsement for RDM. The key to this is getting to know the different stakeholders, their interests and priorities, and thinking strategically about target groups: who are potential allies? Who are the groups who are most hesitant about the importance of RDM? Why are they hesitant? Could allies help with any of these discussions? A particularly powerful example was from someone who had a Nobel Prize winner ally, who knew some of the senior institutional leaders and helped them to get institutional endorsement for their cause.
Can people change?
The question was asked whether anyone had an example of a senior leader changing their opinion, not necessarily about RDM services. Someone suggested that in case of unsupportive leadership, persistence and patience are required and that sometimes it is better to count on a change of leadership than a change of opinions. Another suggestion was that rebranding the service tends to be more successful than hoping for people to change. Again, knowing the stakeholders and their interests is helpful in getting to know what is needed and what kind of rebranding might be appropriate. For example, shifting the emphasis from sharing of research data and open access to supporting good research data management practice and increasing research efficiency was something that had worked well at one institution.
This also led to a discussion about the perception of RDM services and whether their governance structure made a difference to how they were perceived. There was a suggestion that presenting RDM services as endeavours from inside or outside the Library could make a difference to people’s perceptions. At one science-focused institution anything coming from the library was automatically perceived as a waste of money and not useful for the research community and, as a result, all business cases for RDM services were bound to be unsuccessful due to the historic negative perception of the library as a whole. Opinion seemed to confirm that in places where libraries had not yet managed to establish themselves as relevant to 21st century academics, pitching library RDM services to senior leadership was indeed difficult. A suggested approach is to present RDM services as collaborative endeavours, and as joint ventures with other institutional infrastructure or service providers, for example as a collaboration between the library and the central IT department. Again, strong links and good relationships with colleagues at other University departments proved to be invaluable in developing RDM services as joint ventures.
The role of funding bodies
We moved on to discuss the need for endorsement for RDM at an institutional level occurring in conjunction with external drivers. Institutions need to be sustainable and require external funding to support their activities, and therefore funders and their requirements are often key drivers for institutional policy changes. This can happen on two different levels. Funding is often provided on the condition that any research data generated as a result needs to be properly managed during the research lifecycle, and is shared at the end of the project.
Non-compliance with funders’ policies can result in financial sanctions on current grants or ineligibility for individual researchers to apply for future grant funding, which can lead to a financial loss for the University overall. Some funders, such as the Engineering and Physical Sciences Research Council (EPSRC) in the United Kingdom, have clear expectations that institutions should support their researchers in adhering to good research data management practice by providing adequate infrastructure and policy framework support, therefore directly requesting institutions to support RDM service development.
Could funders do more?
There was consensus that funding bodies could perhaps do more to support good research data management, especially given that many non-UK funders do not yet have requirements for research data management and sharing as a condition of their grants. There was also a useful suggestion that funders should make more effort to ensure that their policies on research data management and sharing are adhered to, for example by performing spot-checks on research papers acknowledging their funding to see if supporting research data was made available, as the EPSRC have been doing recently.
Similarly, if funders would do more to review and follow up on data management plans submitted as part of grant applications it would be useful in convincing researchers and senior leadership of the importance of RDM. Currently not all funders require that researchers submit data management plans as part of grant applications. Although some pioneering work aiming to implement active data management plans started, people taking part in the discussion were not aware of any funding body having a structured process in place to review and follow up on data management plans. There was a suggestion that institutions should perhaps be more proactive in working together with funders in shaping new policies. It would be useful to have institutional representatives at funders’ meetings to ensure greater collaboration.
Future directions and resources
Overall we felt that it was useful to exchange tips and tricks so we can avoid making the same mistakes. Also, for those who had not yet managed to secure endorsement for RDM services from their senior leaders it was reassuring to understand that they were not the only ones having difficulty. Community support was recognised as valuable and worth maintaining. We discussed what would be the best way of ensuring that the advice exchanged during the meeting was not lost, and also how an effective exchange of ideas on how best to engage with senior leadership should be continued. First of all we decided to write up a blog post report of the meeting and to make it available to a wider audience.
Secondly, Jisc agreed to compile the various resources and references mentioned and to create a toolkit of techniques with examples for making RDM business cases for RDM. An initial set of resources useful in making the case can be found on the Research Data Network webpages. The current resources include A High Level Business Case, some Case studies and Miscellaneous resources – including Videos, slide decks, infographics, links to external toolkits, etc. Further resources are under development and are being added on a regular basis.
The final tip to all RDM service providers was that the key to success was making the service relevant and that persistence in advocating for the good cause is necessary. RDM service providers should not be shy about sharing the importance of their work with their institution, and should be proud of the valuable work they are doing. Research datasets are vital assets for institutions, and need to be managed carefully, and being able to leverage this is the key in making senior leadership understand that providing RDM services is essential in supporting institutional business.
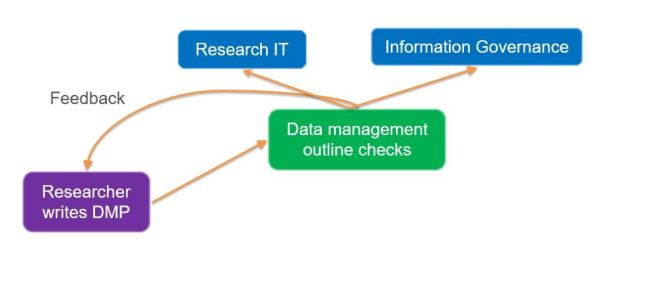
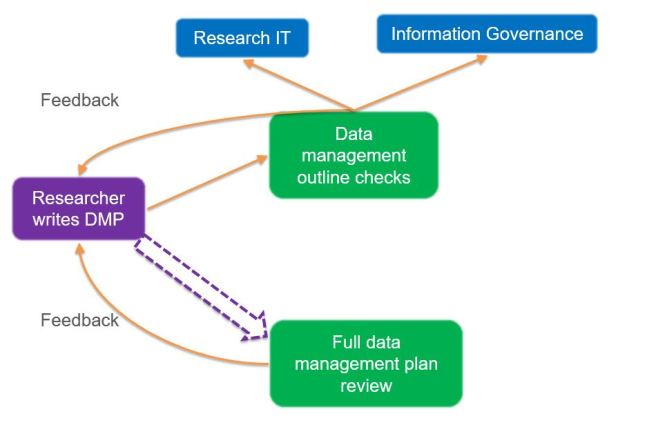
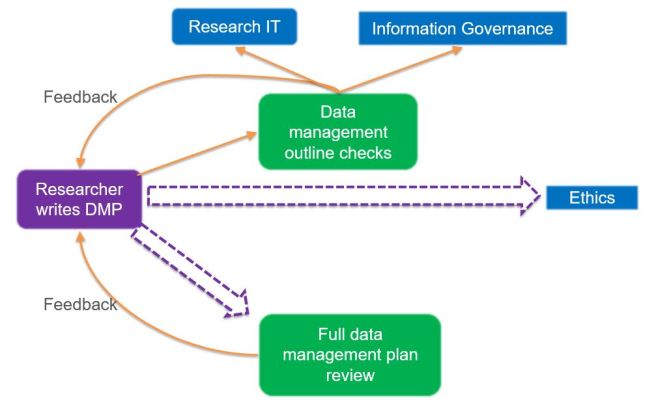



 Having presented our respective plans to the RDM Forum (
Having presented our respective plans to the RDM Forum ( There are two solutions to this problem which were mentioned during the breakout session. Firstly, some people are using a ‘train the trainer’ approach to involve other research support staff who are based in departments and already have regular contact with researchers. These people can act as intermediaries and are likely to have a good awareness of the discipline-specific issues which the researchers they support will be interested in.
There are two solutions to this problem which were mentioned during the breakout session. Firstly, some people are using a ‘train the trainer’ approach to involve other research support staff who are based in departments and already have regular contact with researchers. These people can act as intermediaries and are likely to have a good awareness of the discipline-specific issues which the researchers they support will be interested in.